使用AI标注快速训练自己的实例分割数据集
标注自己的数据集
准备工作
首先创建一个文件夹datasets_seg;
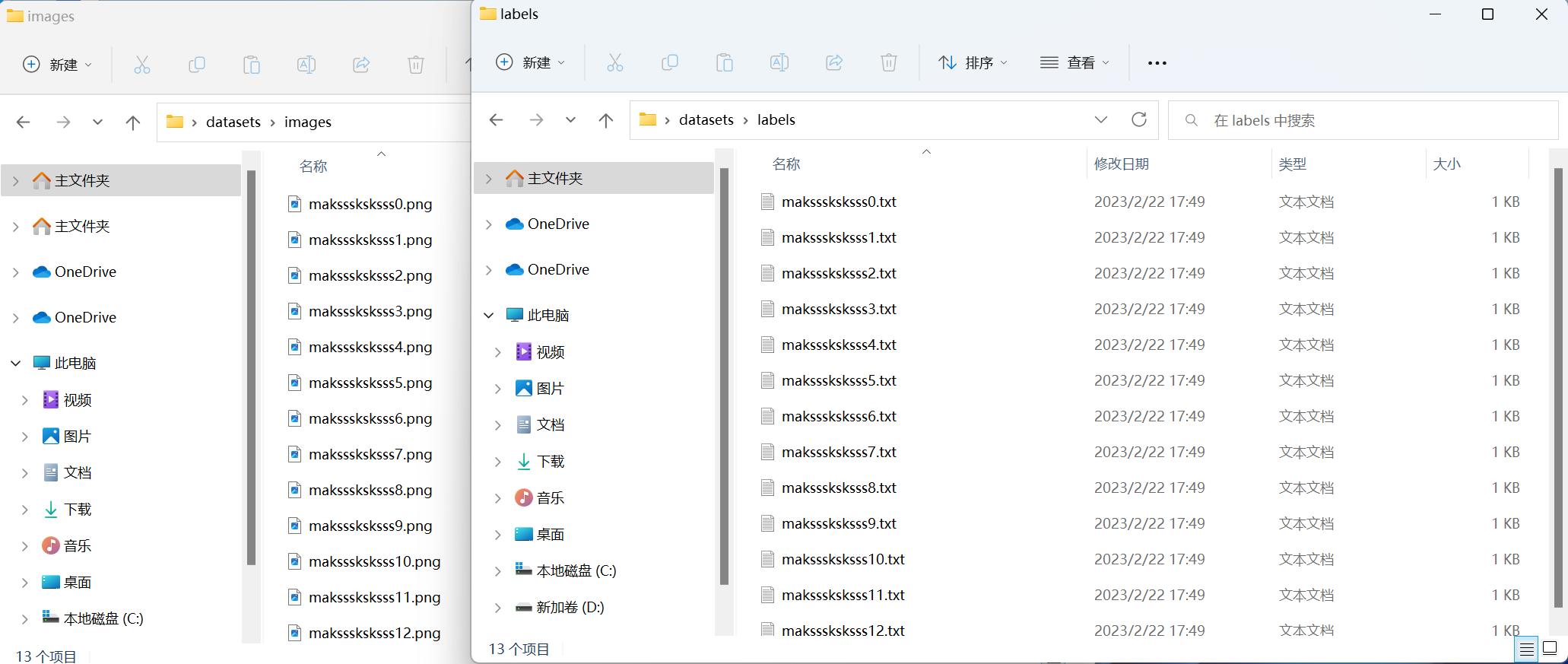
在其中创建一个子文件夹 images,将需要标注的图片(≥100张)放入images文件夹中;
在“images”同路径下新建一个名字为labels的文件夹,用来存放标注过程中生成的标签文件;
在“images”同路径下新建一个名字为xxx.yaml的空文件(如该数据集为口罩检测,则命名为mask_seg.yaml);
准备好的数据集文件夹如下图所示:

标注数据
双击并运行label_Object_Mask.exe;
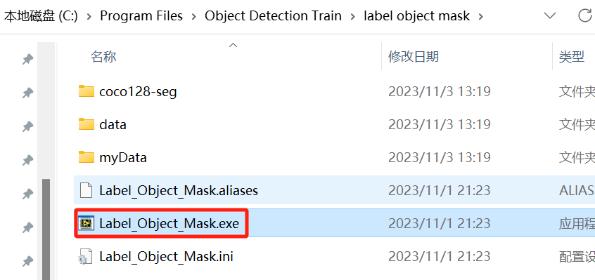
启动之后,这就是软件的界面:

打开需要标注的数据集文件夹datasets_seg,选择“当前文件夹”;
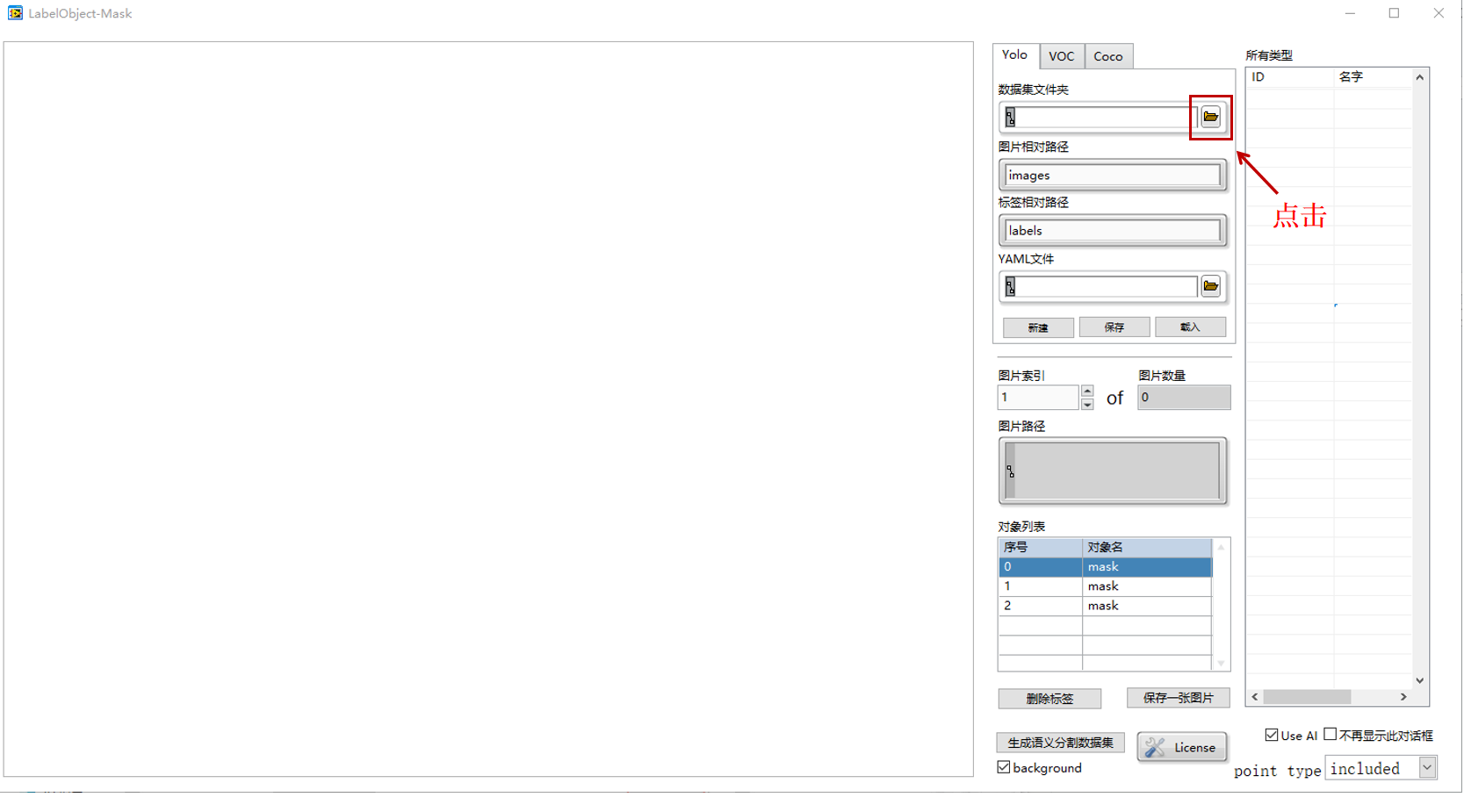

同样的选择并加载yaml文件,加载后如下图所示:

修改图片和标签相对路径为如下图所示:

点击“载入”,可以看到图片区域已经加载好了待标注图片;
请注意:如果该图片没有感兴趣的区域,不需要将该图片放到该数据集中

右边一栏“所有类型”当前什么也没有,可以自己编辑,但ID必须从0开始,逐个加1,标签名字必须是英文(如口罩分割一共一个标签,mask),添加所有要标记的标签;

添加完毕一定要如下图所示点击保存,然后点击OK,否则无法保存标签名字;

注意:后续如果新增了标签类型,即所有类型中新增了ID和名字,也请记得一定要点击保存。
开始标注,将鼠标滑动到图片区域,单击需要标注区域的左上角开始标注,弹出选择点的类型对话框,选择point type为top left corner,点击确定,出现绿点,再单击标注区域的右下角,选择point type为bottom right corner,点击确定,出现蓝点,最后再单击标注区域,选择point type为included,并勾选不再显示此对话框,点击确定,出现红点,双击鼠标完成标注;





标注选项:可以通过程序的右下角,勾选不再显示此对话框,根据需求在程序的右下角选择point type:选择top left corner鼠标点击目标区域的左上角、选择bottom right corner鼠标点击目标区域的右下角、选择included后鼠标单击标注区域、当目标框住不需要标注的区域时,可以选择not included后鼠标单击不需要标注的目标区域;

区域标注:可以在标注区域多点红点,确保目标区域标注完整;
完成以后,双击标注区域,会弹出标签框,可以开始创建标签,也可在下拉框中选择对应标签,点击OK;

此时对象列表里面就有这个对象了;

如果图片中还有其他待标注物体,那么重复9,10两步。这个图标注好以后,点“保存一张图片”,就把标注信息存起来了,只要点击了“保存一张图片”了,关掉软件下次再继续标注也没问题。
点击左边“图片索引”向上箭头,点击OK标注下一张图片。

若有框错或者框对应的标签选错,则可在对象列表中选中该行,点击“删除标签”;

全部图片标注完成后,关闭label_Object_Mask;
此时打开labels文件夹,里面是多个txt格式的标签文件,文件名称与图片名称一一对应;
打开txt标签文件,里面的每一行代表图片中的一个多边形框。每一行从左到右依次是:种类序号(红框)、不规则框坐标(每两个为一个坐标,如[0.359375 0.314208]),用空格隔开;

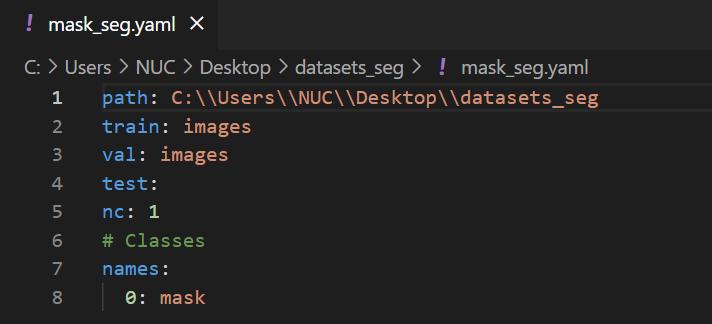
打开xxx.yaml,可看到格式如下:
训练数据集
设置参数
双击运行ObjectDetection Training.exe界面如下图所示:
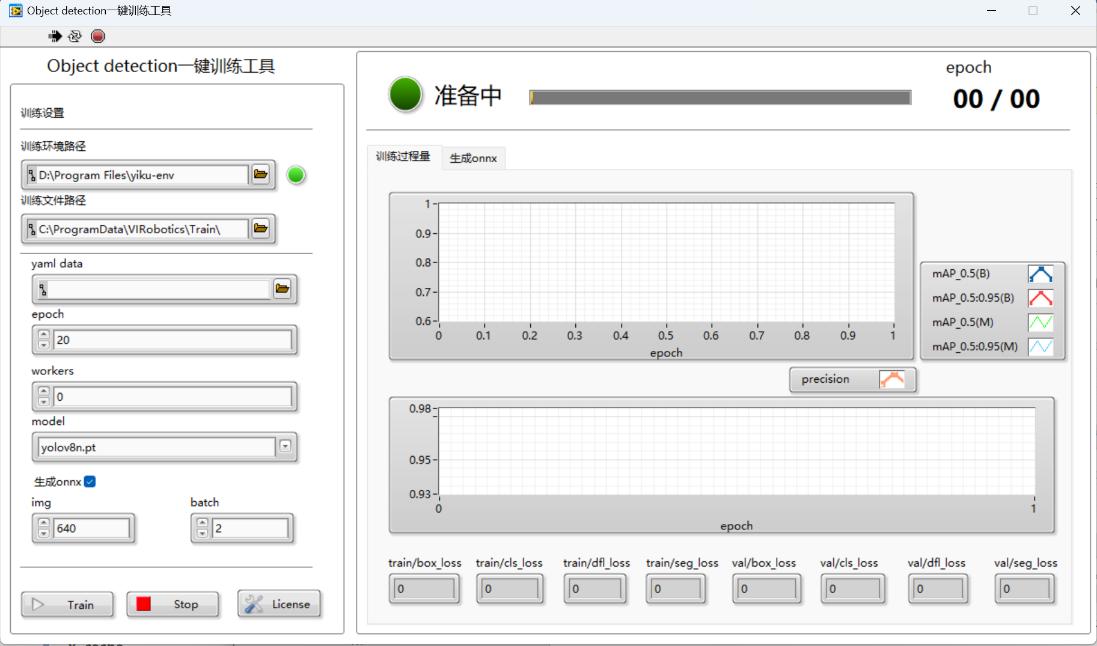
训练文件路径:即预训练模型文件和训练之后生成的模型文件存放路径,默认为:C:\ProgramData\VIRobotics\Train\yolov8,大家可以根据需要自己选择,需要注意:路径不要包含中文或空格;
yaml data: 数据文件的路径。该参数指定了数据集文件的位置,例如 coco128-seg.yaml。数据集文件包含了训练和验证所需的图像、标签。演示中选择的是标注生成的xxx.yaml;

epoch:训练轮数。默认为20;这个参数确定了模型将会被训练多少次,每一轮都遍历整个训练数据集。设置数值越大,训练时间越久,模型精度越高,我们可以设置大一些比如100来找到模型的更佳性能;
workers:默认为0,如果电脑显存较大,可以试试将workers设置为1;
model: 预训练模型:默认为yolov8n.pt,我们需要更换为seg模型,预训练模型例如yolov8n-seg、yolov8s-seg、yolov8m-seg、yolov8l-seg、yolov8x-seg。n、s、m、l、x预训练权重越来越大。预训练模型权重越大,训练出来的模型精度相对来说越高,但训练和检测的速度也会越慢。

img:输入图像的尺寸,默认为640。这个参数确定了输入图像的大小。可以指定一个整数值表示图像的边长,建议为32的整数倍。(设置策略:如果数据集中存在大量小对象,增大输入图像的尺寸imgsz可以使得这些小对象从高分辨率中受益,更好的被检测出)
batch: 每个批次中的图像数量。在训练过程中,数据被分成多个批次进行处理,每个批次包含一定数量的图像。这个参数确定了每个批次中包含的图像数量,默认为8。一般认为batch越大越好。batch越大选择的这个batch中的图片更有可能代表整个数据集的分布,从而帮助模型学习。但batch越大占用的显卡显存空间越多,如果训练过程中出现GPU显存溢出的报错或者内存不足,可将该值设置的小一点,GPU对2的幂次的batch可以发挥更佳的性能;
若希望训练之后直接生成onnx模型,勾选“训练后生成onnx”,训练结束后会自动弹出生成的onnx模型,该格式的模型可以直接用于仪酷AI系列工具包的推理部署;
开始训练
所有参数配置好了之后,点击Train;
弹出的框中点击“是的”开始进行训练;

训练过程会弹出cmd黑框,请不要关闭,训练完毕会自动关闭,首次训练会自动下载一些必要的文件以及预训练模型,这将会耗费一点时间;
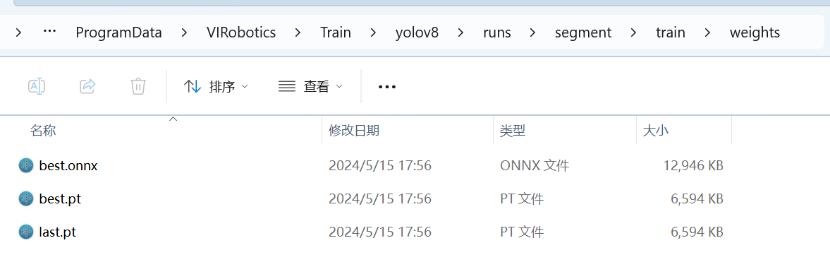
如下图所示训练了20个epoch,黄色进度条满格,则表示整个数据集已经训练完毕,训练生成的pt模型输出在C:\ProgramData\VIRobotics\Train\yolov8\runs\segment\train\weights文件夹中;
【注:多次训练时,输出路径的train会自动变为train2、train3 … 以此类推。】
如果对本次训练的结果不满意,可以用上述的best.pt 或last.pt 作为预训练模型再次训练,而不必用yolov8n-seg.pt 从头开始训练,操作方法如下:将best.pt复制到C:\ProgramData\VIRobotics\Train\yolov8文件夹下,修改model控件中的yolov8n-seg为best.pt,点击Train再次开始训练。
导出为onnx模型
若在训练之前,勾选了训练后生成onnx,则在训练完成后会弹出生成的onnx及所在路径提示框;
点击OK,完成本次训练,可根据实际检测效果来判断是否要继续进行训练;
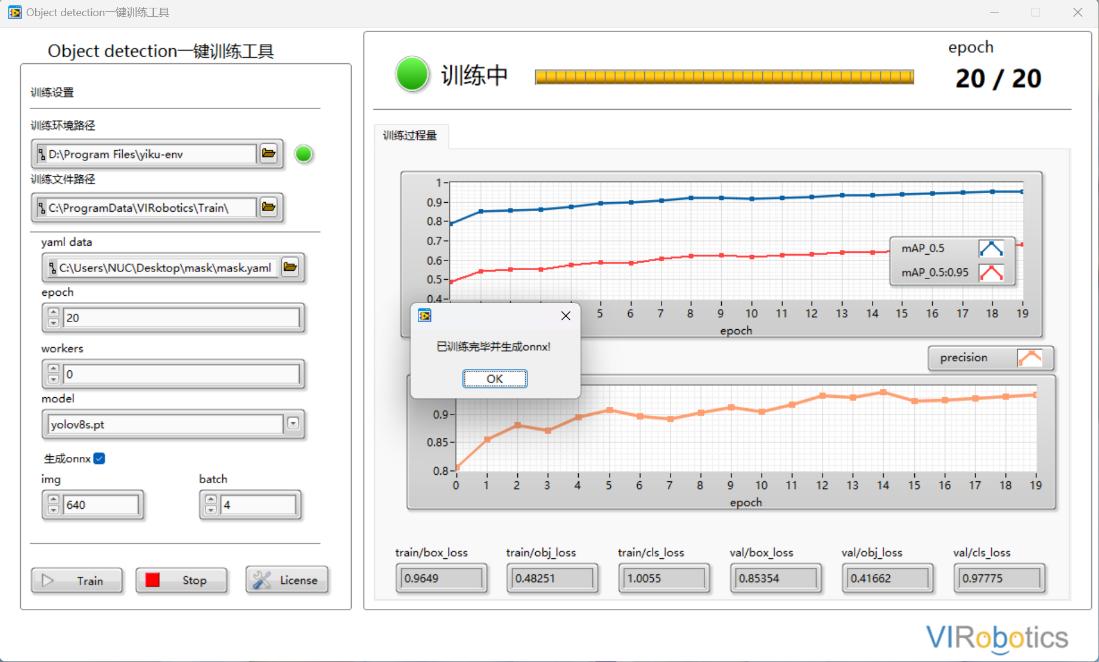
导出的onnx可以直接用于仪酷AI系列工具包的推理和部署;
常见问题
如在标注或训练过程遇到问题,可查看故障排除
如果您遇到了无法解决的问题,请联系我们的支持团队寻求帮助。联系邮箱: support@virobotics.net